Forecasting Accuracy Targets

Before you set forecasting accuracy targets, or beat yourself up (or anyone else for that matter) for not being accurate, there are a number of key considerations. In fact in many cases it may simply be more time-effective to mitigate the effect of forecast errors rather than invest time attempting to further fine-tune forecasting models if the forecast errors are generally being caused by essentially random variation in demand.
The following outlines some typical factors that will increase or decrease how forecastable a demand volume really is in reality.
Size Matters
It is in general easier to attain a good forecast accuracy for larger sized volumes. If you are only receiving one or two contacts per day, even a one-unit random variation in contact will result in a large percentage forecast error, whereas large volumes will lend themselves to leveling out random variation or at least reduce the risk of impact.
Aggregation
Doubling up on size mattering, forecast accuracy will improve with the level of aggregation. When aggregating or over time, the same effect of larger volumes will dampen the impact of random variation. This means that forecast accuracy measured at a group level is more likely to achieve higher accuracy than when forecasting individual products/services. Likewise, the forecast accuracy measured on a monthly or weekly aggregation basis rather than a daily basis is also usually significantly higher.
How far in the future
Short-term forecasts are more accurate than long-term forecasts. A longer forecasting horizon will significantly increases the chance of changes not known to us yet having an impact on future volume. This is particularly true when workload has a strong correlation to short term events, such as weather-dependent demand.
Dispersion
One way to determine how random variation impacts your ability to forecast, is to determine how much dispersion exists (how spread out numbers are) in your workload volume flow i.e how consistent and stable are contact arrival patterns. This is important because the higher the dispersion the harder it is to get an accurate forecast by using historical data alone.
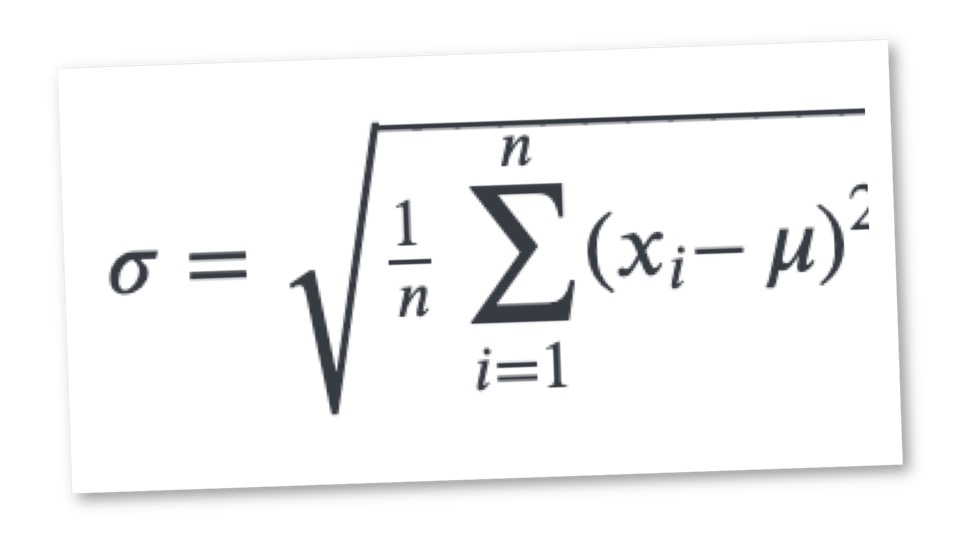
The best way to measure deviation in volume demand is to use ‘Standard Deviation’ to compare like for like time intervals. For example you could measure the total contacts on a Monday for the last 4 weeks or on an intra-day basis – 9am on Monday for the last 4 weeks ect ect. . The more spread apart the data, the higher the deviation.
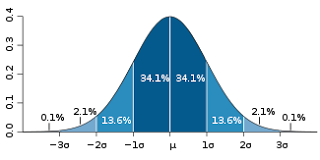 Graph depicts what is considered to be a normal variance distribution, and each band is considered 1 standard deviation. If your call flow is sitting in SD1 near to the middle (highly unlikely) then the chance of accurately forecasting using historical data alone are very high.
Graph depicts what is considered to be a normal variance distribution, and each band is considered 1 standard deviation. If your call flow is sitting in SD1 near to the middle (highly unlikely) then the chance of accurately forecasting using historical data alone are very high.

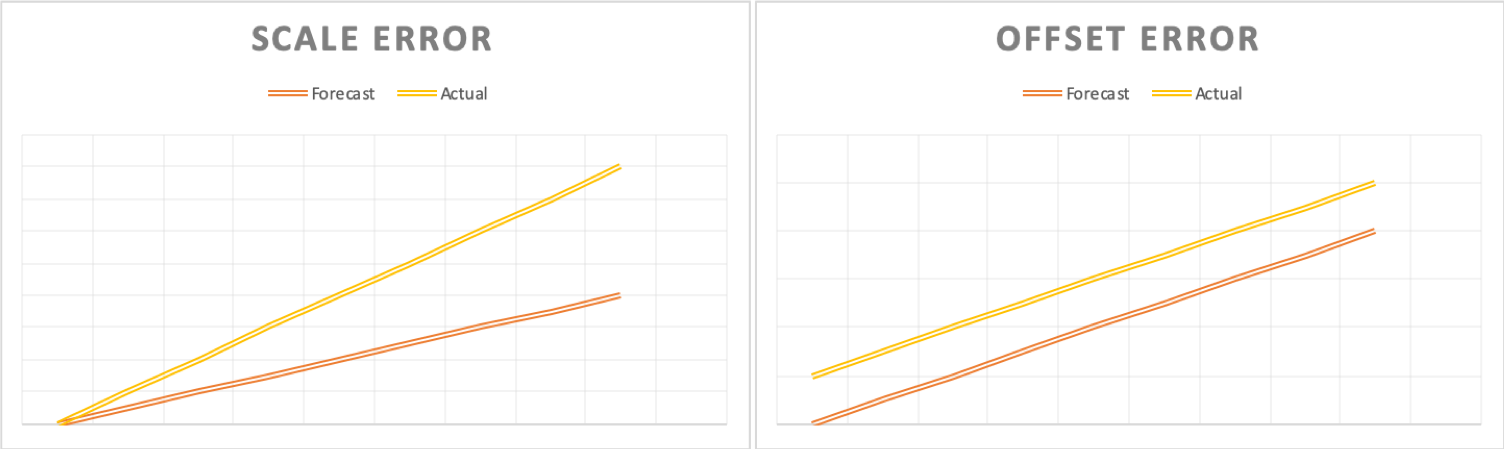
Not all dispersion starts equally. For example to what level variation is is caused by random variation vs how much is systematic (variation which is deterministic via demand drivers) provides an important guide not only to future forecasting method improvements but also the level of accuracy you are likely able to achieve. Systematic errors are usually easy to spot, they are consistent and repeatable errors and generally fall into two categories “scale” or “offset”. Scale factor errors generally are proportional in nature whilst Offset Errors are following the same trend but incorrect level.



Responses