Time-Series Forecasting

In his article “The FUTURE of WFM” (click here to read), Blair talked about how the Erlang formulas have been at the heart of determining staffing requirements for a long time and he pointed out some of the challenges around using this basic formula for today’s complex contact centres. Of course whatever model you use to determine staffing requirements, if you put rubbish into a model you will get rubbish out no matter what method you are using.
Back in 2012 one of the first articles I wrote was about “volume forecast” (click here to read) or in the case of a call centre the number of calls forecasted to be offered. This of course could just as easily be webchats offered, email’s offered, or other types of back office admin offered for an agent to complete depending upon the channel you are forecasting. Along with other key assumptions such as handle time (how long is piece of work going to take to complete) this is a key component to be fed into the staffing requirement model.
The volume forecasting article still remains the number 1 most popular post of all time for this blog, attracting 23,541 pageviews (at the time of writing this article) so on that basis I suspect some further information on this topic might be of interest.
In the original article I mentioned there are 2 main methods if you put aside guesswork – not that you should dismiss this completely as there is a time and place even for guesswork. In this article I am going to focus on time-series methods and the types of models that exist today that feasibly could be used for contact centre forecasting, depending on the granularity of intervals and the data you have available.
In essence time-series methods covers situations that are based solely on past history in order to extrapolate forward as a forecast. Typically a time-series forecast will look to capture elements such as the current level, trend (is it going up or down) and seasonal patterns. Obviously without trend or seasonal patterns, a time series method would just generate a flat-line forecast.
Common Time Series Methods
There are a number of time series methods and they can be generalised into three broad categories; Simplistic (conceptually linear), Holt-Winters exponential smoothing and Box-Jenkins (ARIMA) method.
Simplistic Method

This includes moving averages (simple, cumulative, or weighted forms) percentage growth (the difference between two values in time) and a line of best fit (least square method). The “simplistic” label is a giveaway but there are benefits to using these methods such as being able to produce results quickly and without any strong statistical expertise by the analyst.
Interestingly most WFM systems often rely on simplistic forecasting method with the most common form being weighted moving averages to allow for some seasonality and trend. This often can be enough especially where there are strong leading indicators, low volatility and you are not attempting to reach too far into the future with the forecast. However as contact centres continue to become more complex to forecast many workforce planning analysts are using tools (often excel) outside of the WFM system to complement their forecasting process because more accurate forecasts can almost always be generated using other time series methods.
Holt-Winters exponential smoothing method (triple exponential smoothing)
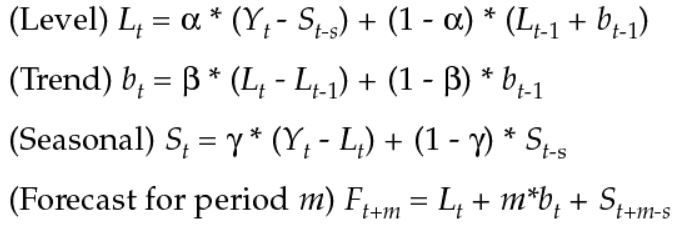
So I could not write a whole article without putting some formula down… please forgive my inner geek making an appearance.
This method typically performs well in terms of accuracy, and in many cases is an easy enough method to create in excel. Holt-Winters method in simple terms is a way to structurally model three aspects of the time series; a typical starting value (level), a slope over time (trend), and a cyclical repeating pattern (seasonality). Each of these three variables are adaptive and can even be calibrated using excel solver. If you want to know more about this method there is plenty of information online I have even found youtube videos with step by step guides on how to build a version of the model in excel – click here for an article with more information. In summary exponential smoothing is ideal when there is a lack of data points or when arrival is too volatile for more complex models such as Box–Jenkins.
Box-Jenkins (ARIMA) models.

Both George Box (pictured left) and Gwilym Jenkins were British statistician’s so a little bit of national pride on my part to include them.
Box-Jenkins models are similar to exponential smoothing models in that trends and seasonal patterns are adaptive, however whilst they can be automated they remain too complex (on the whole) for excel to cope, requiring specialised software languages such as Python or C++ in order to transform the data to a state where meaningful analysis can be applied. ARIMA also differs in that it relies on autocorrelations (patterns in time) rather than a more structural method of adapting level, trend and seasonality. Box-Jenkins models tend to perform better than exponential smoothing models when there is more data availability and arrivals are less volatile (stable) i.e. when the past is a stronger predictor of the future.
Which method is best?

So there is lot of method here, but this not a “how to guide” (although if you are interested in learning there is a lot of free information out there on the web) and perhaps this article creates more questions than it answers. For example which method is best? The simple answer is none of the above methods are best in every scenario. Selecting the most appropriate method is often achieved by using the analyst’s expert knowledge and experience of the data at hand. It is also recommended that experiments are conducted of the various methods and a selection is made that produces the least variance when comparing past actual’s against what you would have forecasted with the data at hand at that time.
And of course a combination of the above through multilevel forecasting can achieve great results on paper. It should however be said that I am yet to see where the time and effort needed to produce multilevel forecasting in a contact centre environment outweighs the value in forecasting accuracy it provides. It is usually reserved for the manufacturing sector when levels in the forecasts are needed in different hierarchies (eg product hierarchy, customer hierarchy, region hierarchy). I would be very interested to hear from someone who differs in their experience however.
So I will end on perhaps a slightly controversial note, the most accurate method is not always the best method. As mentioned in the Measuring Forecast Error (Click here), constantly measuring your accuracy is key and methods such as MAPE will tell you the size of your forecast error, and Poisson (as described in Ger Koole’s article “What is the best achievable forecast accuracy?” (click here)) will tell you the probability of a deviation and its likely impact on accuracy to help determine what size of error objective is fair i.e. many forecasting error objectives are set at a 5% deviation objective but when volumes are small, fluctuations in volume can makes it near impossible to obtain that objective.
However neither MAPE or Poisson will tell you how efficiently you are forecasting or even whether the different methods you are using are making the forecast better or worse. To determine this there is very simple process called forecast value added (FVA). It requires a little extra effort upfront but in the long run can really add accuracy value and reduce forecasting man-hour cost by helping you to avoid pointless forecasting processes. It basically uses the simplest, least labor intensive method of forecasting (namely a “naïve” forecast) to benchmark against the forecasting accuracy of each of the stages in your current process.
Until next time – Peace! / Peace out.


Responses