When Average Handle Times (AHT’s) can be misleading

As I wrote in a past article Average Handle Time (AHT) – Metrics That Matter, there is no doubt about it, the good old Average handle time (AHT) metric is an important metric in workforce management workload forecasting. In fact, any type of moving average metric is extremely useful for forecasting long-term trends.
Now I am going to tell you why they can also be next to useless…
Why outliers are the enemy of the Average as a predictor
Any use of an average for the purpose of assumptive forecasting can be misleading when the distribution is heavily skewed at either end of the tail. In fact, even a small number of outliers can pull the average in that direction and give the misimpression that the handle time is clustering around a point that is higher or lower than where they truly are clustering.
Depending on where that data point lies in a normalized distribution of data points (the “bell curve”), the probability that the average is accurately describing or predicting the behaviour/outcome of handle time comes purely down to how the distribution approaches the tails of the curve. Basically, the wider the outlier the less reliable any assumption (not just AHT) as a predictor.
For example: Let’s say that the current average handle time (AHT) is 404 seconds, and you normally operate at an AHT of 450. The fact that you operating 46 seconds quicker must mean there has been a productivity improvement, right? Wrong in this case. That average number is completely skewed by a mass of super-quick conversations. c.1000 of those contacts are taking 2000 seconds and c.4000 of those contacts are taking a mere 5 seconds. Now imagine how alarming this insight would be, whereas before we were applauding the productivity improvement now we know we have an unusually large number of short contacts, indicating perhaps some sort of connectivity issue, and very likely causing the need for the customer to reconnect which is driving up offered volume and destroying your Service Level – we also have some unusually long conversations indicating complexity and difficultly and perhaps again some sort of issue.

If you’re merely looking at averages, you’re probably missing the data that’s of greatest importance. Outliers might be your worse enemy to the “Average” as a predictor but they are mighty useful to help you to discover problems.
How to know when the Average (mean) is a good predictor
As we mentioned earlier when the data becomes skewed, the average loses its ability to provide the best central location because the data will drag it away from the typical value as was show in the above example.
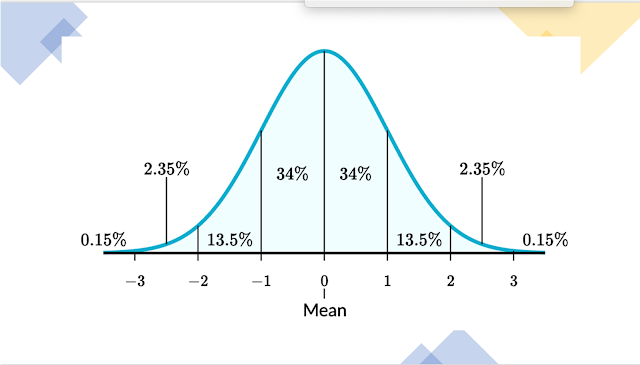
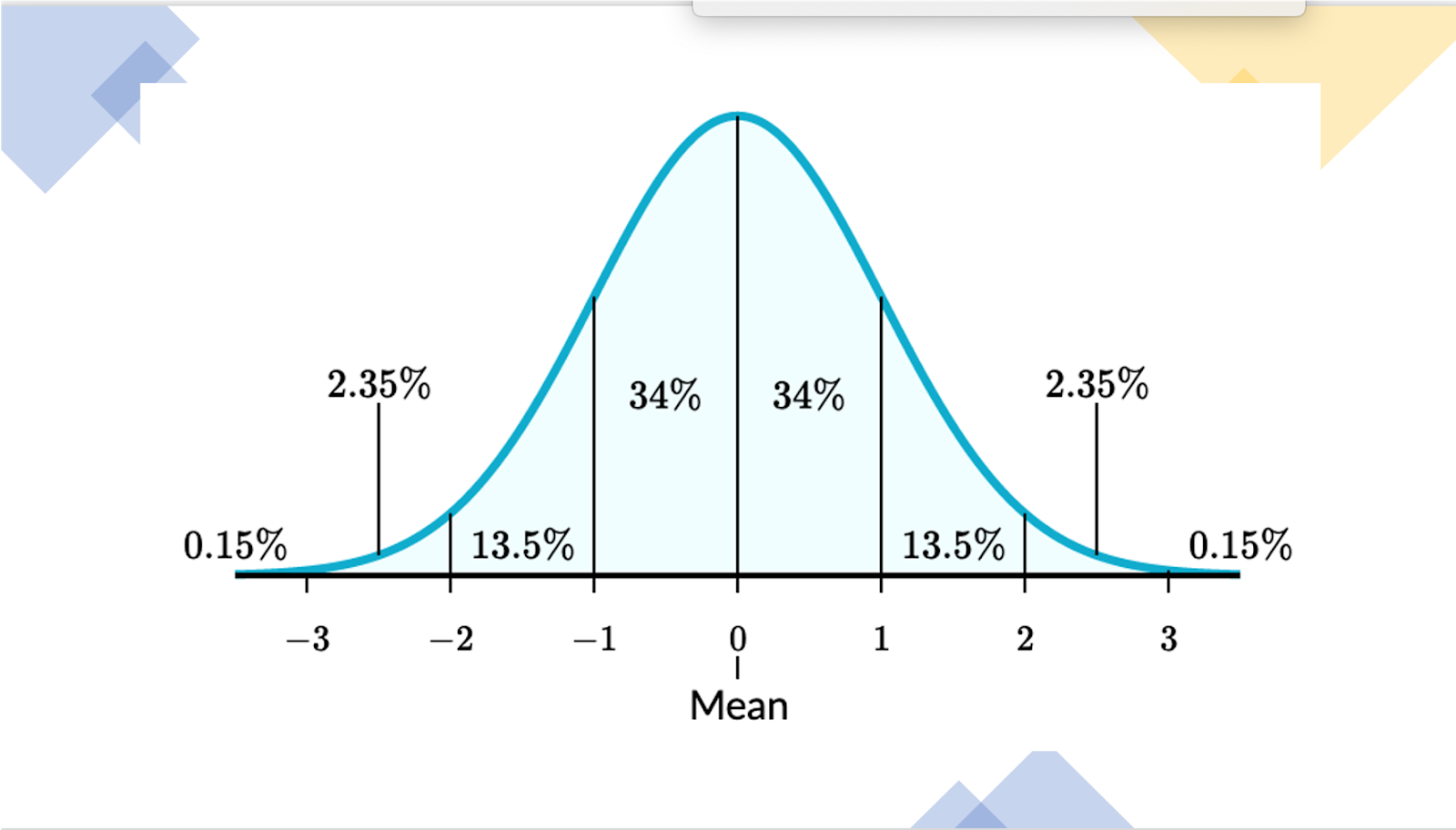
So, to determine whether the Average (mean) will be a good predictor you are looking to see how close your dataset is to following a normal distribution.
Normal distributions have the following features:
· symmetric bell shape
· mean and median are equal; both located at the center of the distribution
· 68%, percent of the data falls within 1 standard deviation of the mean
· 95%, percent of the data falls within 2 standard deviations of the mean
· 99.7%, of the data falls within 3 standard deviations of the mean
A quick test you can perform to discover whether your data is roughly following a normal distribution is to compare the Average (mean) of your dataset with the Median – if they are very similar this is a positive indication.
Basically you are looking for the data you are comparing to be mostly mostly uniform, say 68% of your datapoint falling within 1 standard deviation of the mean then you can safely use the average (mean) aggregator.
But if your data has extreme scores (outliers), then you need to consider using median, which is less susceptible to outliers and extreme values, to filter out the values that are skewing the results.


Responses