Methods to Measure Forecast Error

The first rule of forecasting is that all forecasts are either wrong or lucky. However failing to learn from when your forecasting is wrong or lucky makes it a lot less likely forecasting accuracy will improve over time. The first and most beneficial purpose of accuracy analysis is to learn from your mistakes after all you can’t manage what you don’t measure.
As with so many areas of forecasting, there is no single ‘best’ measure that can be used to describe forecasting accuracy. For typical operational forecasting a combination of MAPE, FVA and Exception Analysis are the dream ticket but I will come onto why a little later in this article.
- Mean Absolute Percentage Error (MAPE)
- Weighted Mean Absolute Percent Error (WMAPE)
- Mean Percentage Error (MPE)
- Error Total (ET)
- Exceptions Analysis
Each of these measures have their pro’s & con’s but context is everything especially regarding which measure should be used for what situation, highly dependant on what you are your forecasting. FVA and Exceptions Analysis as methods are slightly different from the first 6 above and I will go into a little more depth later on in this article on when and how to use.
The overall accuracy of any forecasting method, no matter which method you use, is determined by comparing the forecasted values with actual values. However to help determine which of the first 6 methods fits best for your situation it is important to first understand the two main types of error measurement:
Error Sign – In simple terms this error type helps determine whether you want to treat Positive and Negative Forecast Error the same or different i.e. will it make any difference to you if Forecast is more than Actual or less than Actual. Usually in operational planning setting’s both types of error can be equally harmful, however if you were forecasting for say perishable products then you would always prefer the Forecast to be less than Actual as surplus production is as good as loss.
Error Spread – this error type helps determine whether it is important that the forecast error is concentrated into a few points or spread evenly across many e.g. do you mind if the forecast goes horribly wrong on a few points as long it is accurate for the entire horizon. Again shelf life of the item plays a big part here. For example a live channel customer contact (on say Phone or Chat) has a very short shelf life (you have until the customer abandon their attempt) whilst answering a customer email has a longer shelf life which means an email unanswered in one period can be effectively put into use in subsequent periods and thus it is less impactful if the forecast goes wrong in one period as long as we make up for that in accuracy across a broader horizon.
Here is a quick reference table that shows which Forecasting Accuracy measurement weighting towards Error Sign and Error spread:

As mentioned already for operational workload forecasting either a positive or negative “Error Sign” is usually equally harmful, with either a positive error or a negative error either resulting in under or over staffing. As a result, often the three most popular accuracy methods tend to be Mean Absolute Deviation (MAD), Mean Squared Error (MSE) and/or Mean Absolute Percent Error (MAPE).
However, a common problem for both MAD and MSE is that their values depend on the magnitude of the item being forecast. For example, if the forecast item is measured in thousands, the MAD and MSE results can be very large – not so good for typical operational planning workload forecasting unless your organisation is huge. So this leaves us with MAPE.
MAPE or WMAPE
Given the limitations of MAD and MSE this logically take us to MAPE. MAPE in its traditional form is computed as the average of the absolute difference between the forecasted and actual values and is expressed as a percentage of the actual values. MAPE is perhaps also the easiest measure to interpret and remains undistorted by any single large value.
However, a major difficulty that arises with MAPE is that if there is any instance where the base in any individual percent error calculation is zero, the result cannot be calculated. This is often referred to as the divide by zero problem. Various workarounds have been used to deal with this issue, but none of them are mathematically correct. Perhaps the biggest problem arises when MAPE is used to assess the historical errors associated with different forecasting models with a view to selecting the best model. Thus, MAPE is totally unsuitable for assessing in this way any item with an intermittent demand pattern.
Also when calculating the average MAPE for a number of time series, you may encounter a problem: a few of the series that have a very high MAPE might distort a comparison between the average MAPE of a time series fitted with one method compared to the average MAPE when using another method.
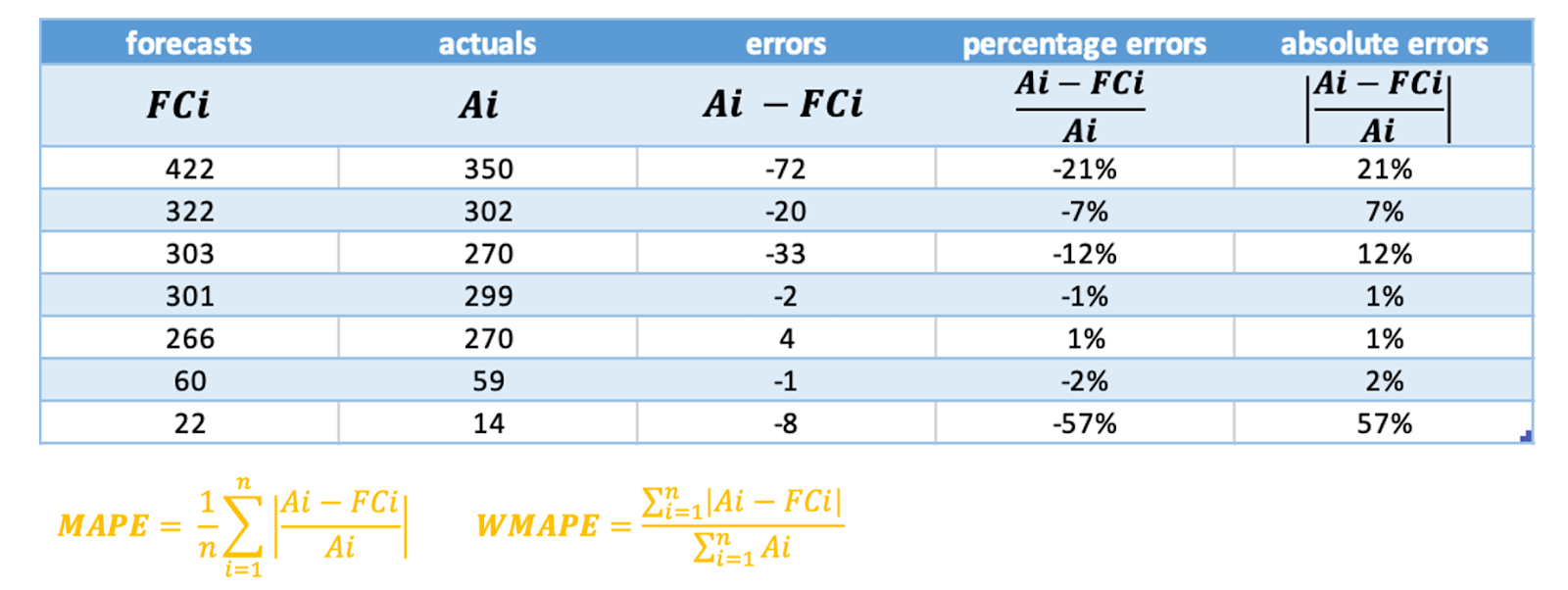
The disadvantage of MAPE is immediately clear from the above example: a large percentage error for a small actual can cause a large MAPE. In this example, the result for the last day explains more than half of the MAPE.
In order to avoid this problem, other measures have been defined, for example the SMAPE (symmetrical MAPE), weighted absolute percentage error (WAPE), real aggregated percentage error, and relative measure of accuracy (ROMA).
My personal favourite is WAPE mainly because of simplicity and ease to calculate. There is a very simple way to calculate WMAPE. This involves adding together the absolute errors at the detailed level, then calculating the total of the errors as a percentage of total volume. This method of calculation leads to the additional benefit that it is robust to individual instances when the base is zero, thus overcoming the divide by zero problem that often occurs with MAPE.
WMAPE is a highly useful measure and is becoming increasingly popular both in corporate KPIs and for operational use. It is easily calculated and gives a concise forecast accuracy measurement that can be used to summarise performance at any detailed level across any grouping of products and/or time periods. If a measure of accuracy required this is calculated as 100 – WMAPE.
Forecast Value Added (FVA)
WMAPE will tell you the size of your forecast error which of course is very important, however what it won’t tell you is how efficient you are forecasting, help you understand the drivers or underlying true variability, what should be the minimum error rate, or even whether the different methods and models you are using are making the forecast better or worse.
To determine this, I advise you use a very simple process called Forecast Value Added (FVA). It requires a little extra effort upfront but in the long run can really add accuracy value and reduce forecasting man-hour cost by helping you to avoid pointless forecasting processes. It basically uses the simplest, least labour-intensive method of forecasting (namely a “naïve” forecast) to benchmark the forecasting accuracy at each of the stages in your current process. For example how much accuracy is being added by causal factors and is the leadership review adding value or biased views?

The above diagram is from a typical forecasting process, by running FVA you are able to answer the following questions;
- Are all the stages in your forecasting process actually adding accuracy?
- Is the effort expended at each stage actually worth it?
- Where in the process are your weak points?
Exception Analysis
Summary measurement such as WMAPE are useful for tracking accuracy over time. However, exceptions analysis aims to identify and explain the reasons for the biggest / most expensive forecast errors, providing opportunity to learn from errors and potentially apply the lessons of experience to future forecasts.
The whole point of measuring the accuracy of your forecast is to improve it, and the only way I know of doing this is to try and understand why you have a gap.
It is therefore important you also include in your method a process for rapidly identifying the exceptions – those big deviations that caused the most problems and ask yourself the simple question could the causes have been anticipated? If so, you now have clearly identified that better information or interpretation in this space will improve future forecasts. A very simple high-level process to follow for exception analysis is:
1. Exception Analysis Preparation– Define rules that will be used to identify and classify exceptions.
2. Mining Phase. Apply algorithms to the data to identify exceptions based on pre-defined rules.
3. Research exceptions – look for supporting information on cause of these exceptions.
4. Submit changes to forecast – If the research changes the forecast and/or resolves the exception.
For example, an influx of customer contacts in the morning throughout the whole month will likely be built into the next forecast if you are using any type of historical method. However, knowing why this has happened informs you whether you should be including/excluding/smoothing this data for future forecasts. If the influx of calls was a result of a one-off TV advert being played during the mornings of that month only, would you want to include this in future forecasts?



Responses