Introduction to Simple Forecasting Methods


Forecasting is one of the most important aspects in business. We use the techniques to anticipate the future.
In business, the forecasting is used to allocate the manpower, budget etc. Forecasting is so powerful that all the business planning relies on forecasting.
Fortunately, the contact center forecasting comes under WFM bucket and due to this, WFM is looked as a very important and pivotal department in an organisation.
There are numerous methods of forecasting available and each has its own calculations and usage.
Today, in this we are going to look at some simple forecasting methods along with their calculations. We will also look at how to select a best fit model depending upon the Forecast Accuracy/Error.
As always, I have attached a excel sheet at the end which contains detailed calculations of the Simple Forecasting Methods.
So, let’s begin our quest!!
- Naive Forecasting Method or Random Walk Method
The logic of Naive Forecasting Method is that the forecasted values will be equal to the previous period value. The Naive Method is also called as Random Walk Method.
For e.g., if we are forecasting for the month of January, the forecasted value will be equal to December. This is illustrated by a formula as shown below.
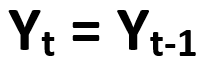
where, Yt is the period to be forecasted and Yt-1 is the previous period.
- Seasonal Naive Forecasting Method or Seasonal Random Walk Method
This is a slightly improved method over the Naive to factor the seasonality. While the forecasters were using the Naive Method, they had a problem of the previous seasonality not getting factored in the forecast.
Therefore the Seasonal Naive Method was formulated.
Let us consider that we have to forecast for the month of January and we have the previous year forecast as historical. Now, instead of considering December as the forecasted value for January as we did in Naive method, we will consider the previous year January value for the current year January.
This is illustrated by a formula as shown below.
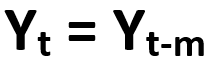
where, Yt is the period to be forecasted and Yt-m is the previous seasonal period.
- Random Walk with Drift
We know that the Naive and Seasonal Naive are also called as Random Walk. In this method we use the Seasonal Random Walk, but with an additional component called drift.
For any historical data, we have certain forecast components such as Level, Trend and Seasonality. These are called the “Building blocks of Forecasting”. I would urge the reader to clink on this link to read more on the Building blocks of Forecasting. Contact Center Basic Forecasting Building Blocks
Anyways, coming back to the drift. Since we are using Seasonal Random Walk, the seasonality part of the forecast is taken care of, the actual historical value acts as a Level.
Therefore the only pending component is the Trend. To factor this in our forecast, we use the additional drift component to our forecasting.
Let’s take a look at the below formula for Random walk with Drift.

The formula may look at little overwhelming, but it is very easy when you do it in excel. Please refer to the attachment.
- Moving Average Method
This is perhaps the most common method used in forecasting. As the name indicates, this is a technique where we consider the average of subset of previous data as the forecasted value.
As we move towards the forecast period, the subset also moves, therefore the name Moving Average.
The Moving Average is denoted by MA(n) and n stands for the period of the subset. We read it as Moving Average of Order n.
For e.g. if we have monthly call volume data for a year and we are trying to forecast the value for the next 4 months, we can use the average of the first four months of previous data for Month 1. When we move to Month 2, the average also moves to the next four month excluding the 1st month and including the 5th month. Thus the average move as we progress to our forecast.
In the excel file attached below, i have considered the subset to be 4, therefore the moving average is denoted as MA(4).
The key to get the best forecast accuracy is by changing the size of subset and finding the best size by doing a trail and error method.
Below is the formula for Moving Average.

- Weighted Moving Average Method
In the moving average, we gave equal importance to all the values in the subset. However there are instances where the most recent historical value has some external factor to it such as Marketing, New Product etc.
In this scenario, we cannot give equal weights to all the value in a subset. Therefore we use the Weighted Moving Average Method.
The Weighted Moving Average is denoted by WMA(n) and n stands for the period of the subset. We read it as Weighted Moving Average of Order n.
The most recent historical value gets more weightage and the weightage reduces as we go further to the past. However all the weights added together should be equal to 1 or 100%.
In the excel file attached below, i have considered the subset to be 4 and the weights as 10%, 20%, 30% and 40%, therefore the weighted moving average is denoted as WMA(4).
The key to get the best forecast accuracy is by changing the size of subset and changing the weights and finding the best size and weights by doing a trail and error method.

- How to find the best fit model?
We have looked at different simple forecasting models above, but how do we decide which model is the best fit for our data?
To understand this, we have to look at the different ways of looking at the forecasting error. Let us first look below at few terms which are required to calculate the forecast accuracy.
Error: The difference between the forecasted value and the actual value.
Absolute Error: The absolute difference between the forecasted value and the actual value.
Square of Error: The square of the Absolute Error.
Once we have understanding of the above terms, we will proceed to calculate three different types of forecasting error.
- MAE (Mean Absolute Error): Average of the Absolute error for all the time period.
- RMSE (Root Mean Square Error): Square Root of the Average of the Squared Error for all time period.
- MAPE (Mean Absolute Percentage Error): Average of Absolute Error divided by the average of actual value for all the time period
With the example in the attached excel file, below are the values of MAE, RMSE and MAPE.

Just by looking at the above numbers, it is very obvious that for the given data set, the Seasonal Naive has the lowest error. Therefore the Seasonal Naive Method or Random Seasonal Naive is the best fit model for forecasting.
Note: These methods are tried and tested in R and Python
Attachment: Simple Forecasting Model
Thank you for Reading????????
Stay Tuned!!
Disclaimer: This article is purely my personal view and understanding, this doesn’t depict any organisation data



Responses